Table of Contents
Psst. Do you already know segmented logs well? If yes, jump here.
Prologue: The Log 📃🪵
First, let's clarify what we mean by a "log" in this context. Here, log refers to an append only ordered collection of records where the records are ordered by time.
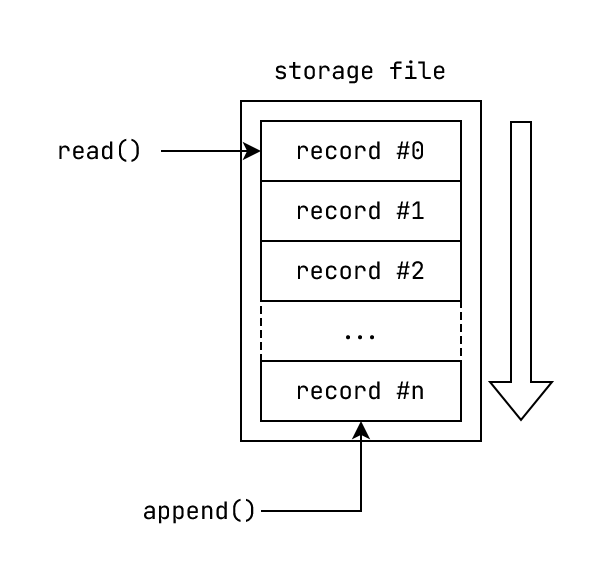
Fig: The Log: An append only ordered collection of records.
Since the records are ordered by time, the log's record indices can be thought of as timestamps, with the convenient property of being decoupled from actual wall-clock time.
The log indices effectively behave as Lamport clock timestamps.
A lamport clock is a logical counter to establish causality between two events. Since it's decoupled from wall-clock time, it's used in distributed-systems for ordering events.
So, why do we care about these kinds of logs? Why are they useful?
Log Usage: An example scenario
There's a teacher and a set of students in a classroom. The teacher wants to hold an elementary arithmetic lesson.
The teacher makes every student write down a particular initial number. (e.g 42). Next, the teacher plans to give a sequence of instructions to the students. The teacher may give the following kinds of instructions:
- Add x; where x is a number
- Sub x; where x is a number
- Mul x; where x is a number
- Div x; where x is a non-zero number
For every instruction, the students are to apply the instruction to their current number, calculate the new number, and write down the new number as their current number. The students are to continue this process for every instruction, till the teacher finishes giving instructions. They are then required to submit the final calculated number to the teacher.
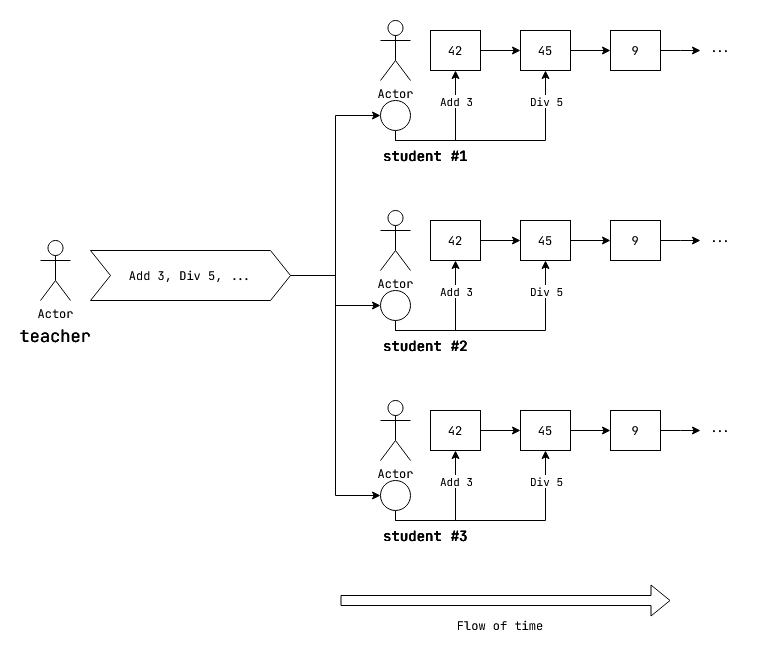
Fig: Sample scenario with initial number 42.
So for instance, if the current number is 42, and the received instruction is
Add 3, the student calculates:result = Add 3 (current_number) = current_number + 3 = 42 + 3 = 45 current_number = result ;; 45Next if the student receives,
Div 5:result = Div 5 (current_number) = current_number / 5 = 45 / 5 = 9 current_number = result ;; 9
Now, if all students start from the same initial number, and apply the same sequence of operations on their number, they are bound to come to the same result! So the teacher also gives the students a self grading lesson by telling the final number at the end of the class. If the student got the same final number, they scored full marks.
Notice that the students must follow the following to get full marks:
- Start from the same correct initial number
- Apply all the operations correctly in the given order, without random mistakes in the correct pre-determined way.
With computer science, we can model the students as deterministic state machines, the students' current_number as their internal state, and the instructions as inputs to the state machines. From here, we can say the following:
If different identical deterministic state machines start from the same initial state, and receive the same set of inputs in the same order, they will end in the same state.
We call this the state machine replication principle.
State machine replication
Now there's a new problem: the last two rows of students can't hear the teacher properly. What do they do now? The teacher needs a solution that enables them to give the same set of instructions to the backbenchers without actually giving them the answers.
The solution here is to give the instructions in writing. However, in an exercise to foster teamwork between their students, the teacher delegates the instruction sharing task to the students.
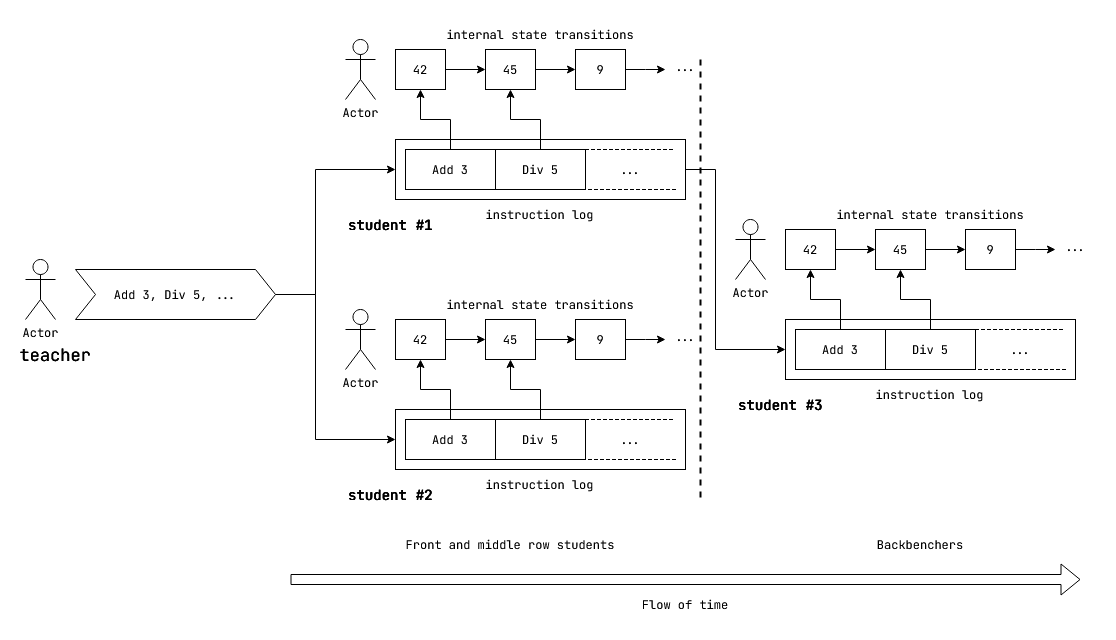
Fig: Log based state machine replication between front, middle and back benchers.
The students come up with the following solution:
They first write down the instructions sequentially on sheets of paper, and then perform the calculations separately on their own private sheet. When they are done writing on a sheet of paper with the instructions, they only share the sheet containing the instructions. They never share their private sheet. After passing a sheet full of instructions, they start writing the subsequent instructions on a new sheet of paper.
The backbenchers are able to receive the same set of instructions in the same sequence through the sheets. They perform the necessary calculations on their own private sheet starting from the same initial number using the instructions from the received sheets.
If we inspect carefully, this mechanism of sharing the instructions through the sheets behaves like a log. The private sheets act as the internal states. The collection of sheets collectively act as a log.
Now, in our case, because the backbenchers receive the same set of instructions in the same sequence, they go through the same set of internal states in the same sequence and arrive at the same final state. They effectively replicate the front and middle-benchers. Since, we can model students as state machines, we effectively did state machine replication with a log.
Finally, since the backbenchers receive the instructions through the log and not directly from the teacher, they lag behind a bit but eventually arrive at the same results. So we can say there is a replication lag.
These concepts directly translate to distributed systems. Consider this:
There is a database partition in a distributed database responsible for a certain subset of data. When any data manipulation queries are routed to it, it has to handle the queries. Instead of directly committing the effect of the queries on the underlying storage, it first writes the operations to be applied on the local storage, one-by-one into a log called the "write-ahead-log". Then it applies the operations from the write ahead log to the local storage.
In case there is a database failure, it can re-apply the operations in the write-ahead-log from the last committed entry and arrive at the same state.
When this database partition needs to replicate itself to other follower partitions, it simply replicates the write-ahead-log to the followers instead of copying over the entire materialized state. The followers can use the same write ahead log to arrive to the same state as the leader partition.
Now the follower partitions, have to receive the write-ahead-log first over the network. Only then can they apply the operations. As a result they lag behind the leader. This is replication lag.
Asynchronous processing
Now in the same classroom scenario, what happens when a student is absent? Turns out they still need to do the assignment.
The backbenchers come to the rescue! They share the ordered sheets of instructions and the initial number with the student in distress. The student gleefully applies the instructions on the number, arrives at the same results and scores full marks.
However, notice what happened here: The student did the assignment in a completely out of sync or asynchronous way with respect to the other students.
Logs enable asynchronous processing of requests.
Message queues provide a convenient abstraction over logs to enable asynchronous processing. A server might not be able to synchronously handle all requests due to lack of resources. So instead, it can buffer the requests in a message queue. A different server can then pick up the requests one-by-one and handle them.
Now it's not necessary that all the requests have to be handled by the same server. Because the log is shared, different servers may choose to share the load with each other. In this case, the requests are distributed between the servers to load-balance the requests. (Provided that there is no causal dependency between the requests.)
For instance, a simple scheme might be: If there are N servers, the server for a particular request is decided with request.index % N.
If you want to read more about the usage of logs in distributed systems, read Jay Krep's (co-creator of Apache Kafka) excellent blog post on this topic here.
Segmented Log 🪚🪵
It might come as a surpise, but we have already come across a segmented log in the previous example.
Introduction
In the previous example, the collection of sheets containing the instructions collectively behaved as a log. We can also say that the instruction log was segmented across the different sheets of paper.
Call the individual sheets of paper segments. The collection of sheets can now be called a segmented log.
Let's go back to the log. At the end of the day a log is sequential collection of elements. What's the simplest data structure we can use to implement this?
An array.
However, we need persistence. So let's use a file based abstraction instead.
We can quite literally map a file to a process's virtual memory address space using the
mmap()system call and then use it like an array, but that's a topic for a different day.
Fig: A log implementation based on a file.
Since our file based abstraction needs to support an append only data-structure, it internally sequentially writes to the end of the internal file. Assume that this abstraction allows you to uniquely refer to any entry using it's index.
Now, this setup has some problems:
- All entries are sequentially written to a single large file
- A single large file is difficult to store, move and copy
- Few bad sectors in the underlying disk can make the whole file unrecoverable. This can render all stored data unusable.
The logical next step is to split this abstraction across multiple smaller units. We call these smaller units segments.
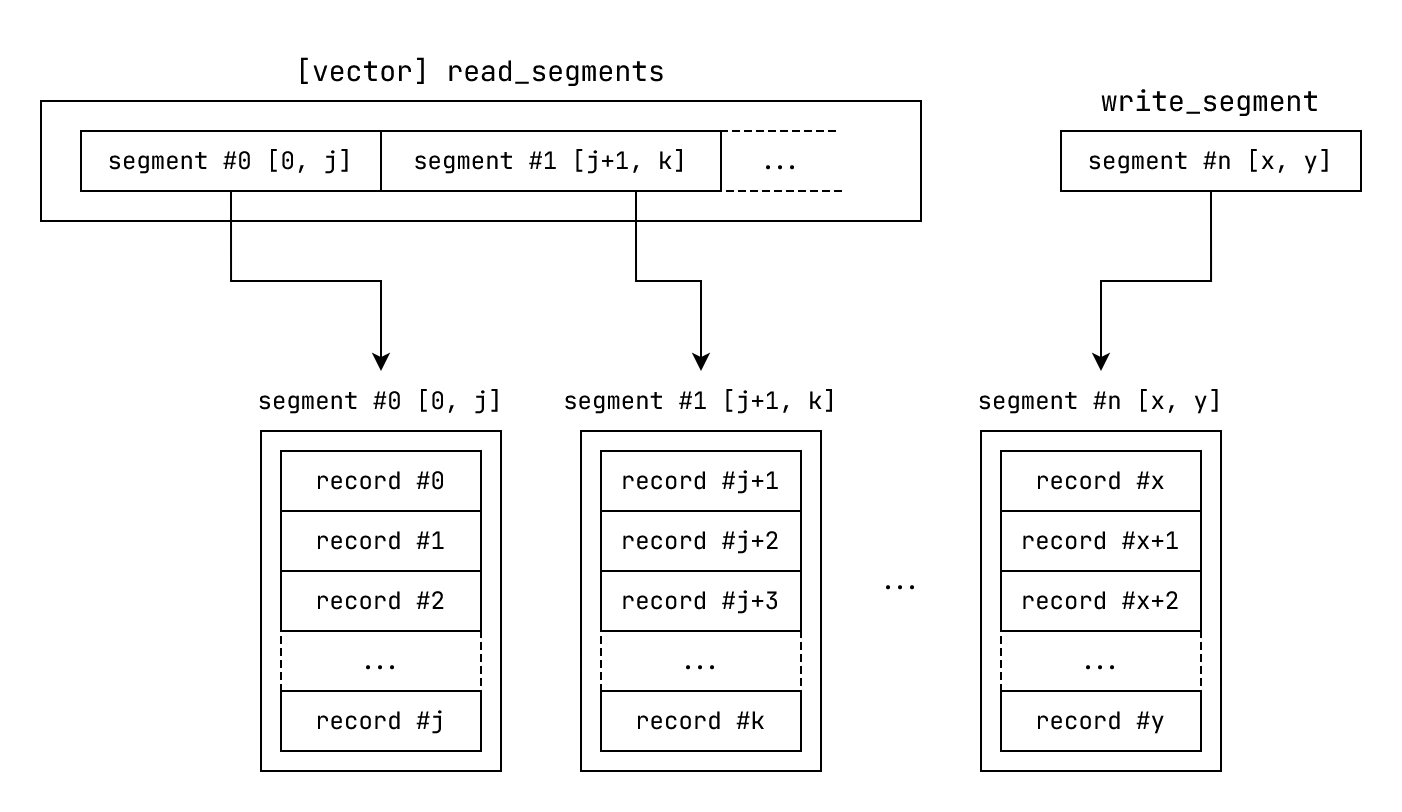
Fig: segmented_log outline.
In this solution:
- The record index range is split across smaller units called segments. The index ranges of different segments are non-overlapping.
- Each segment individually behaves like a log
- For each segment we maintain an entry:
segment. Thissegmententry stores the index range serviced by it along with a handle to the underlying file - We keep the
segmententries sorted by their starting index - The first n - 1 segments are called read segments. Their
segmententries are stored in a vector calledread_segments - The last segment is called the write segment. We assign it's
segmententry towrite_segment.
Write behaviour:
- All writes go to the
write_segment - Each
segmenthas a threshold on it's size - When the
write_segmentsize exceeds it's threshold:- We close the
write_segment - We reopen it as a read segment.
- We push back the newly opened read segment
segmententry to the vectorread_segments. - We create a new
segmentwith it index range starting after the end of the previous write segment. Thissegmentis assigned towrite_segment
- We close the
Read behaviour (for reading a record at particular index):
- Locate the
segmentwhere the index falls within thesegment's index range. Look first in theread_segmentsvector, fall back towrite_segment - Read the record at the given index from the located
segment
Original description in the Apache Kafka paper
This section presents the segmented_log as described in the Apache Kafka paper.
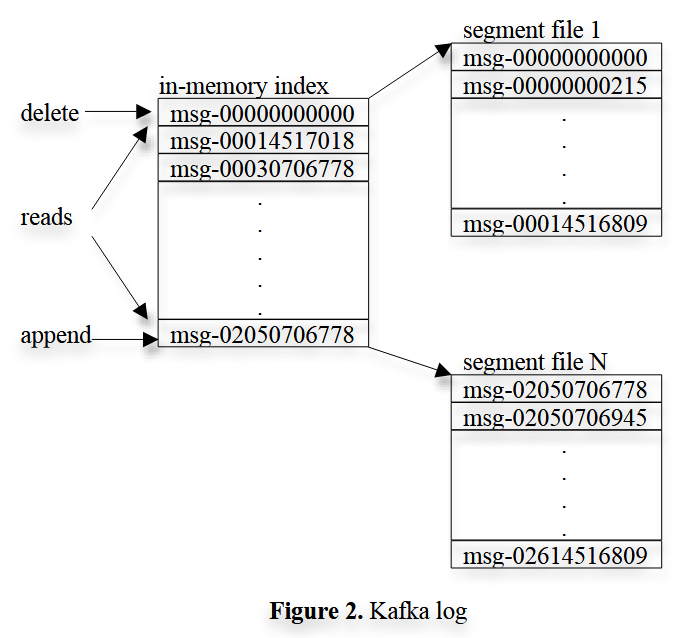
Fig: segmented_log (Fig. 2) from the the Apache Kafka paper.
Simple storage: Kafka has a very simple storage layout. Each partition of a topic corresponds to a logical log. Physically, a log is implemented as a set of segment files of approximately the same size (e.g., 1GB). Every time a producer publishes a message to a partition, the broker simply appends the message to the last segment file. For better performance, we flush the segment files to disk only after a configurable number of messages have been published or a certain amount of time has elapsed. A message is only exposed to the consumers after it is flushed.
Unlike typical messaging systems, a message stored in Kafka doesn’t have an explicit message id. Instead, each message is addressed by its logical offset in the log. This avoids the overhead of maintaining auxiliary, seek-intensive random-access index structures that map the message ids to the actual message locations. Note that our message ids are increasing but not consecutive. To compute the id of the next message, we have to add the length of the current message to its id. From now on, we will use message ids and offsets interchangeably.
A consumer always consumes messages from a particular partition sequentially. If the consumer acknowledges a particular message offset, it implies that the consumer has received all messages prior to that offset in the partition. Under the covers, the consumer is issuing asynchronous pull requests to the broker to have a buffer of data ready for the application to consume. Each pull request contains the offset of the message from which the consumption begins and an acceptable number of bytes to fetch. Each broker keeps in memory a sorted list of offsets, including the offset of the first message in every segment file. The broker locates the segment file where the requested message resides by searching the offset list, and sends the data back to the consumer. After a consumer receives a message, it computes the offset of the next message to consume and uses it in the next pull request.
The layout of an Kafka log and the in-memory index is depicted in Figure 2. Each box shows the offset of a message.
The main difference here is that instead of referring to records with a simple index, we refer to it with a logical offset. This is important because the offset is dependent on the record sizes. The offset for next record has to be calculated as the sum of current record offset and current record size.
A segmented_log implementation
The code for this section is in this repository: https://github.com/arindas/laminarmq/ More specifically, in the storage module.
While I would love to discuss testing, benchmarking and profiling, this blog post is becoming quite lengthy. So, please look them up on the repository provided above.
Note: Some of the identifier names might be different on the repository. I have refactored the code sections here to improve readability on various devices. Also there are more comments here to make it easier to understand.
Implementation outline

Fig: Data organisation for persisting a segmented_log on a *nix file system.
A segmented log is a collection of read segments and a single write segment. Each "segment" is backed by a storage file on disk called "store". The offset of the first record in a segment is the base_offset.
The log is:
- "immutable", since only "append", "read" and "truncate" operations are allowed. It is not possible to update or delete records from the middle of the log.
- "segmented", since it is composed of segments, where each segment services records from a particular range of offsets.
All writes go to the write segment. A new record is written at write_segment.next_offset.
When we max out the capacity of the write segment, we close the write segment and reopen it as a read segment. The re-opened segment is added to the list of read segments. A new write segment is then created with base_offset equal to the next_offset of the previous write segment.
When reading from a particular offset, we linearly check which segment contains the given read segment. If a segment capable of servicing a read from the given offset is found, we read from that segment. If no such segment is found among the read segments, we default to the write segment. The following scenarios may occur when reading from the write segment in this case:
- The write segment has synced the messages including the message at the given offset. In this case the record is read successfully and returned.
- The write segment hasn't synced the data at the given offset. In this case the read fails with a segment I/O error.
- If the offset is out of bounds of even the write segment, we return an "out of bounds" error.
Enhancements to the design to enable streaming writes
While the conventional segmented_log data structure is quite performant for a commit_log implementation, it still requires the following properties to hold true for the record being appended:
- We have the entire record in memory
- We know the record bytes' length and record bytes' checksum before the record is appended
It's not possible to know this information when the record bytes are read from an asynchronous stream of bytes. Without the enhancements, we would have to concatenate intermediate byte buffers to a vector. This would not only incur more allocations, but also slow down our system.
Hence, to accommodate this use case, we introduced an intermediate indexing layer to our design.

//! Index and position invariants across segmented_log
// segmented_log index invariants
segmented_log.lowest_index = segmented_log.read_segments[0].lowest_index
segmented_log.highest_index = segmented_log.write_segment.highest_index
// record position invariants in store
records[i+1].position = records[i].position + records[i].record_header.length
// segment index invariants in segmented_log
segments[i+1].base_index = segments[i].highest_index
= segments[i].index[index.len-1].index + 1
Fig: Data organisation for persisting a segmented_log on a *nix file system.
In the new design, instead of referring to records with a raw offset, we refer to them with indices. The index in each segment translates the record indices to raw file position in the segment store file.
Now, the store append operation accepts an asynchronous stream of bytes instead of a contiguously laid out slice of bytes. We use this operation to write the record bytes, and at the time of writing the record bytes, we calculate the record bytes' length and checksum. Once we are done writing the record bytes to the store, we write it's corresponding record_header (containing the checksum and length), position and index as an index_record in the segment index.
This provides two quality of life enhancements:
- Allow asynchronous streaming writes, without having to concatenate intermediate byte buffers
- Records are accessed much more easily with easy to use indices
Now, to prevent a malicious user from overloading our storage capacity and memory with a maliciously crafted request which infinitely loops over some data and sends it to our server, we have provided an optional append_threshold parameter to all append operations. When provided, it prevents streaming append writes to write more bytes than the provided append_threshold.
As we write to segments, the remaining segment capacity is used as the append_threshold. However record bytes aren't guaranteed to be perfectly aligned to segment_capacity.
At the segment level, this requires us to keep a segment_overflow_capacity. All segment append operations now use:
append_threshold = segment_capacity - segment.size + segment_overflow_capacity
A good segment_overflow_capacity value could be segment_capacity / 2.
Component implementation
We now proceed in a bottom-up fashion to implement the entirety of an "indexed segmented log".
AsyncIndexedRead (trait)
If we notice carefully, there is a common thread between Index, Segment and even SegmentedLog as a whole. Even though they are at different levels in the compositional hierarchy, the share some similar traits:
- They allow reading items from specific logical indices
- They have a notion of highest index and lowest index
- The read operation has to be asynchronous in nature to support both in-memory and on-disk storage mechanisms.
Let's formalize these notions:
/// Collection providing asynchronous read access to an indexed set of records (or
/// values).
AsyncTruncate (trait)
Now each of our components need to support a "truncate" operation, where everything sequentially after a certain "mark" is removed. This notion can be expressed as a trait:
/// Trait representing a truncable collection of records, which can be truncated after a
// "mark".
AsyncConsume (trait)
Next, every abstraction related to storage needs to be safely closed to persist data, or be removed all together. We call such operations "consume" operations. As usual, we codify this general notion with a trait:
/// Trait representing a collection that can be closed or removed entirely.
Sizable (trait)
Every entity capable of storing data needs a mechanism for measuring it's storage footprint i.e size in number of bytes.
/// Trait representing collections which have a measurable size in number of bytes.
Storage (trait)
Finally, we need a mechanism to read and persist data. This mechanism needs to support reads at random positions and appends to the end.
"But Arindam!", you interject. "Such a mechanism exists! It's called a file.", you say triumphantly. And you wouldn't be wrong. However we have the following additional requirements:
- It has to be cross platorm and independent of async runtimes.
- It needs to provide a simple API for random reads without having to seek some pointer.
- It needs to support appending a stream of byte slices.
Alright, let's begin:
;
// ... impl Display for StreamUnexpectedLength ...
/// Trait representing a read-append-truncate storage media.
// ...where's streaming append?
First, let's unpack what's going on here:
- We support a notion of
Content, the slice of bytes that is read - We also have a notion for
Positionto identify the position of reads and appends. - First, we have a simple
append_slice()API the simply appends a given slice of bytes to the end of the storage. It returns the position at which slice was written, along with the number of bytes written. - Next, we have a
read()API for reading a slice of bytes of a particularsizefrom a particularposition. It returns aContent, the associated type used to represent slice of bytes that are read from this storage. - Every operation here is fallible. So errors and
Result(s) are natural. However, what's up withStreamUnexpectedLength? Keep that in mind for now. - Our storage can be truncated. We inherit from
AsyncTruncate. We treatPositionas the truncation mark. - Our storage is also consumable. We inherit from
AsyncConsumeforclose()andremove() - Finally, our storage has a notion of size with
Sizable. We use ourPositiontype for representing sizes.
Now, we need to support streaming appends with the existing methods.
Let's begin by asking ourselves, what exactly are the arguments here?
A stream of byte slices. How do we represent that?
Let's start with just a slice. Let's call it XBuf. The bound for that is simple enough:
XBuf:
Now we need a stream of these. Also note that we need the reading of a single item from the stream to also be fallible.
First let's just consider a stream of XBuf. Let's call the stream X:
X:
Now, to let's consider an error type XE. To make every read from the stream fallible, X needs the following bounds:
X:
Now our stream needs to be Unpin so that it we can safely take a &mut reference to it in our function.
This blog post: https://blog.cloudflare.com/pin-and-unpin-in-rust/, goes into detail about why
PinandUnpinare necessary. Also don't forget to consult the standard library documentation:
pinmodule: https://doc.rust-lang.org/std/pin/index.htmlPinstruct: https://doc.rust-lang.org/std/pin/struct.Pin.htmlUnpinmarker trait: https://doc.rust-lang.org/std/marker/trait.Unpin.html
Apart from our Stream argument, we also need a upper bound on the number of bytes to be written. A Stream can be infinite, but unfortunaly, computer storage is not.
Using the above considerations, let us outline our function:
// ... inside Storage trait
async
When append_threshold is None, we attempt to exhaustively read the entire stream to write to our storage. If it's Some(thresh), we only write upto thresh bytes.
Let's proceed with our implementation:
// ... inside Storage trait
async
We maintain a counter for the number of bytes already written: bytes_written. For every byte slice read from the stream, we check if it can be accomodated in our storage in accordance with the append_threshold. If not, we error out.
We also keep the write position around in pos. It is simply the size of this storage before we append anything.
Now, let's try to append it:
// ... inside Storage::append
while let Some = buf_stream.next.await
That's reasonable. We append if possible, and propagate the error. Continuing...
// ... inside Storage::append
while let Some = buf_stream.next.await
So for every byte slice, we add the number of bytes in it to bytes_written if everything goes well. However, if anything goes wrong:
- We rollback all writes by truncating at the position before all writes, stored in
pos. - We return the error encountered.
Finally, once we exit the loop, we return the position at which the record stream was written, along with the total bytes written:
} // ... end of: while let Some(buf) = buf_stream.next().await {...}
Ok
} // ... end of Storage::append
We can coalesce the match blocks together by inilining all the results. Putting everything all together:
/// Error to represent undexpect stream termination or overflow, i.e a stream
/// of unexpected length.
;
/// Trait representing a read-append-truncate storage media.
Now to answer one of the initial questions, we needed StreamUnexpectedLength as a sentinel error type to represent the error case when the stream unexpectedly errors out while reading, or has more bytes in total than our append_threshold.
A sample Storage impl.
Let's explore a tokio::fs::File based implementation of Storage:
First, let's outline our struct:
TokioFileis an alias fortokio::fs::File. It's defined in a use directive in the source.
We need a buffered writer over our file to avoid hitting the file too many times for small writes. Since our workload will largely be composed of small writes and reads, this is important.
The need for RwLock will be clear in a moment.
Next, let's proceed with the constructor for this struct:
As you can see, for the underlying storage file, we enable the following flags:
write: enables writing to the fileappend: new writes are appended (as opposed to truncating the file before writes)create: if the file doesn't exist, it's createdread: enable reading from the file
Now before we implement the Storage trait for StdSeekReadFileStorage, we need to implement Storage's inherited traits. Let's proceed one by one.
First, we have Sizable:
Next, we implement AsyncTruncate:
We also need AsyncConsume:
With the pre-requisites ready, let's proceed with our Storage impl:
Notice that the Storage trait uses a &self for Storage::read. This was to support idempotent operations.
In our case, we need to update the seek position of the file, from behind a &self. So we need some interior mutability to achieve this. Hence the RwLock.
Hopefully, the need for the RwLock is clear now. In retrospect, we could also have used a Mutex but using a RwLock keeps the option of multiple readers for read only operations open.
Note that, the read operation is still idempotent as we restore the old file position after reading.
Record (struct)
Before we move on to the concept of a CommitLog, we need to abstract a much more fundamental aspect of our implementation. How do we represent the actual "records"?
Let's see... a record in the most general sense needs only two things:
- The actual value to be contained in the record
- Some metadata about the record
So, we express that directly:
CommitLog (trait)
Now, with the abstractions presented above, we are ready to express the notion of a CommitLog. The properties of a CommitLog are:
- It allows reading records from random indices
- Naturally it has some index bounds
- It allows appending records which may contain a stream of byte slices as it value.
- It can be truncated at a specific index.
- It supports
close()andremove()operations to safely persist or remove data respectively.
All of these properties have already been represented with the traits above. We now use them to define the concept of a CommitLog:
Optionally, a CommitLog implementation might need to remove some records that are older by a certain measure of time. Let's call them expired records. So we provide a function for that in case different implementations need it.
Index (struct)
Let's start with our first direct component of our indexed segmented log, the Index.
First, we need to answer two primary questions:
- What kind of data are we storing?
- In what layout will we store the said data?
So recall, at a high level, an Index is logical mapping from indices to byte positions on storage.
So this at least has store 2-tuples of the form: (record_index, record_position)
Now we need two additional data points:
- Number of bytes in the record i.e
record_length - A checksum of the contents of the record, e.g. crc32
These two datapoints are essential to verify if the record data is valid or corrupted on the storage media. ("storage media" = Storage trait impl.)
So we arrive at this 4-tuple: (checksum, length, index, position)
Let's call this an IndexRecord.
Now, an Index stores index records sequentially. So:
index_record[i+1].index = index_record[i].index + 1
Now, all these 4-tuples need the exact same number of bytes to be stored. Let's call this size IRSZ. If the index records are laid out sequentially:, every index record will be at a position which is an integral multiple of IRSZ:
## storage (Index)
(checksum, length, index, position) @ storage::position = 0
(checksum, length, index, position) @ storage::position = 1 x IRSZ
(checksum, length, index, position) @ storage::position = 2 x IRSZ
(checksum, length, index, position) @ storage::position = 3 x IRSZ
...
Note: the
positionin the tuple refers to the position of the actualRecordinStore.storage::positionhere refers to the position within theIndexfile (Storageimpl).
Due to this property, the index can be derived from the position of the record itself. The number of records is simply:
len(Index) = size(Index) / IRSZ
Using this, we can conclude that storing the index in each IndexRecord is redundant.
However, an Index can start from an arbitrary high index. Let's call this the base_index. So if we store a marker record of sorts, the contains the base_index, and then store all the index records after it sequentially, we can say:
// simple row major address calculation
index_record_position_i = size(base_marker) + i * IRSZ
So now we can lay out our IndexRecord instances on storage as follows:
## storage (Index)
[base_index_marker] @ storage::position = 0
(checksum, length, position) @ storage::position = size(base_index_marker) + 0
(checksum, length, position) @ storage::position = size(base_index_marker) + 1 x IRSZ
(checksum, length, position) @ storage::position = size(base_index_marker) + 2 x IRSZ
(checksum, length, position) @ storage::position = size(base_index_marker) + 3 x IRSZ
...
Now, number of records is calculated as:
// number of records in Index
len(Index) = (size(Index) - size(base_index_marker)) / IRSZ
Now let's finalize the bytewise layout on storage:
## IndexBaseMarker (size = 16 bytes)
┌───────────────────────────┬──────────────────────────┐
│ base_index: u64 ([u8; 8]) │ _padding: u64 ([u8; 8]) │
└───────────────────────────┴──────────────────────────┘
## IndexRecord (size = 16 bytes)
┌─────────────────────────┬───────────────────────┬─────────────────────────┐
│ checksum: u64 ([u8; 8]) │ length: u32 ([u8; 4]) │ position: u32 ([u8; 4]) │
└─────────────────────────┴───────────────────────┴─────────────────────────┘
We add padding to the IndexBaseMarker to keep it aligned with IndexRecord.
We represent these records as follows:
Since we 32 bytes to represent positions of records, a Segment can contain only be upto 4GiB (232 unique byte positions = 232 bytes = 4GiB). Practically speaking, segments generally don't exceed 1GB. If segments are too big, individual segments are difficult to move around. So this limit is not a problem.
We use binary encoding to store these records.
Now we could use serde and bincode to serialize these records on Storage impls. However, since these records will be serialized and deserialized fairly often, I wanted to serialize in constant space, with a simple API.
First, let us generalize over both IndexBaseMarker and IndexRecord. We need to formalize an entity with the folowing properties:
- It has a known size at compile time
- It can be read from and written to any storage
We can express this directly:
Now we need a kind of SizedRecord that can be stored on a Storage impl. Let's call it PersistentSizedRecord:
/// Wrapper struct to enable `SizedRecord` impls to be stored on Storage impls.
///
/// REPR_SIZE is the number of bytes required to store the inner SizedRecord.
;
Next, we implement the SizedRecord trait for IndexBaseMarker and IndexRecord:
[ Quiz 💡]: We dont read or write the
_paddingbytes in ourIndexBaseMarkerSizedRecordimpl. So how is it still aligned?[ A ]: Remember that we pass in a const generic parameter
REPR_SIZEwhen creating aPersistentSizedRecord. When writing or reading, we always readREPR_SIZEnumber of bytes, regardless of how we serialize or deserialize ourIndexRecordorIndexBaseMarker. In this case we just pass aconst usizewith value16.
We also declare some useful constants to keep things consistent:
/// Extension used by backing files for Index instances.
pub const INDEX_FILE_EXTENSION: &str = "index";
/// Number of bytes required for storing the base marker.
pub const INDEX_BASE_MARKER_LENGTH: usize = 16;
/// Number of bytes required for storing the record header.
pub const INDEX_RECORD_LENGTH: usize = 16;
/// Lowest underlying storage position
pub const INDEX_BASE_POSITION: u64 = 0;
Before we proceed with our Index implementation, let us do a quick back of the handle estimate on how big Index files can be.
Every IndexRecord is 16 bytes. So for every Record we have 16 bytes. Let's assume that Record sizes are 1KB on average. Let's assume that Segment files are 1GB on average.
So we can calculate as follows:
1GB Segment == pow(10, 6) * 1KB Record
1 * 1KB Record => 1 * 16B IndexRecord
pow(10, 6) * 1KB Record => pow(10, 6) * 16B IndexRecord
=> 16MB Index
Or, 1GB Segment => 16MB Index (Result)
e.g. 10 * 1GB segment files => 10 * 16MB Index files = 160 MB overhead
ITB total data through 1000 segment files => 16GB overhead
Keep this calculation in mind as we proceed through our implementation.
With the groundwork ready, let's begin our Index implementation:
Why do we need an in-memory cache in the fist place? Well IndexRecord instances are fairly small and there are usually few of them (<= 1000) in an Index. A simple in-memory cache makes sense rather than hitting the storage everytime. (We could probably mmap() but this is simple enough.)
Alright then, why make it optional?
Recall that for 1TB of data with 1KB record size, we end up having 16GB of Index overhead. It's clearly not practical allocating this amount of memory, since we expect our system to able to handle this scale.
So we make caching IndexRecord instances optional. This would enable us to decide which Index instances to cache based on access patterns.
For instance, we could maintain an LRUCache of Index instances that are currently cached. When an Index outside of the LRUCache is accessed, we add it to the LRUCache. When an Index from within the LRUCache is accessed, we update the LRUCache accordingly. The LRUCache will have some maximum capacity, which decides the maximum number of Index instances that can be cached at the same time. We could replace LRUCache with other kinds of cache (e.g. LFUCache) for different performance characteristics. The Index files are still persisted on storage so there is no loss of data.
I wanted this implementation to handle
1TBof data on a Raspberry Pi 3B. Unfortunately, it has only1GBRAM. However, if we enforce a limit that only10Indexinstances are cached at a time (e.g. by setting theLRUCachemax capacity to10), that would be a160MBoverhead. That would make this implementation usable on an RPi 3B, albeit at the cost of some latency.For storage, I can connect a 1TB external hard disk to the RPi 3B and proceed as usual.
Now, let's define some utilities for constructing Index instances.
Next, we define our constructors for Index:
Next, we define some functions for managing caching behaviour:
Some minor utilities for ease of implementation:
Now, we move on to the primary responsiblities of our Index.
First, let's implement a mechanism to read IndexRecord instances from our Index:
Next, we need a mechanism to append IndexRecord instances to our Index:
We need to be able to truncate our Index:
Finally, we define how to close or remove our Index:
Notice how all of the primary functions of our Index are supported by the traits we wrote earlier.
Store (struct)
Now that we have our Index ready, we can get started with our backing Store. Store is responsible for persiting the record data to Storage.
So remember that we have to validate the record bytes persisted using Store with the checksum and length? To make it easier to work with it, we create a virtual RecordHeader. This virtual RecordHeader is never actually persisted, but it is computed from the bytes to be written or bytes that are read from the storage.
In a previous index-less segmented-log implementation,
RecordHeaderinstances used to be persisted right before every record on theStore. Once we moved recordposition,checksumandlengthmetadata to theIndex, it was no longer necessary to persist theRecordHeader.
We only need a constructor for RecordHeader:
Now we can proceed with our Store implementation:
We also need mechanism for constructing IndexRecord instances from RecordHeader instances once the record bytes are written to the store;
Store also has AsyncTruncate, AsyncConsume and Sizable trait impls, where it delegates the implementation to the underlying Storage impl.
Now that we have our Store and Index ready, we can move on to our Segment.
Segment (struct)
As we have discussed before, a Segment is the smallest unit in a SegmentedLog that can act as a CommitLog.
In our implementation a Segment comprises of an Index and Store. Here's how it handles reads and appends:
- For reads, it first looks up the
IndexRecordinIndexcorresponding to the given record index. With theposition,lengthandchecksumpresent in theIndexRecord, it reads theRecordserialized bytes from theStore. It then deserialize the bytes as necessary and returns theRecordrequested. - For appends, it first serializes the given
Record. Next, it writes the serialized bytes to theStore. Using theRecordHeaderandpositionobtained fromStore::append, it creates theIndexRecordand appends it to theIndex
Now that we know the needed behaviour, let's proceed with the implementation.
First, we represent the configuration schema for our Segment:
When these limits are crossed, a segment is considered "maxed out" and has to be rotated back as a read segment.
Next, we define our Segment struct:
I will clarify the generic parameters in a while. However, we have an additional requirement:
We want to enable records stored in the segmented-log, to contain the record index in the metadata.
In order to achieve this, we create a new struct MetaWithIdx and use it as follows:
Here's what I want to highlight:
- We create a struct
MetaWithIdxto use as the metadata value used forcommit_log::Record. - Next we create a type alias
commit_log::segmented_log::Recordwhich uses theMetaWithIdxstruct for metadata.
Why am I saying all this? Well I did need to clarify the module structure a bit, but there's another reason.
Let's go back to our Segment struct and describe the different generic parameters:
S:Storageimpl used forIndexandStoreM: Metadata used as generic parameter to theMetaWithIdxstruct (this is why I needed to explain howMetaWithIdxfits in first)H:Hasherimpl used for computing checksumsIdx: Type to represent primitive used for for representing record indices (u32,usizeetc.)Size: Type to represent record sizes in bytes (u64,usizeetc)SERP:SerializationProviderimpl used for serializing metadata.
So here's what the SerializationProvider trait looks like:
use Deref;
use ;
/// Trait to represent a serialization provider.
It's used to generalize over different serde data formats.
Now, we need a basic constructor for Segment:
Next, we express the conditions for when a segment is expired or maxed out.
Before, we proceed with storing records in our segment, we need to formalize the byte layout for serialized records:
// byte layout for serialzed record
┌───────────────────────────┬──────────────────────────────┬───────────────────────────────────────────────┐
│ metadata_len: u32 [u8; 4] │ metadata: [u8; metadata_len] │ value: [u8; record_length - metadata_len - 4] │
└───────────────────────────┴──────────────────────────────┴───────────────────────────────────────────────┘
├────────────────────────────────────────── [u8; record_length] ───────────────────────────────────────────┤
As you can see, serialized record has the following parts:
metadata_len: The number of bytes required to represent serializedmetadata. Stored asu32in4bytes.metadata: The metadata associated with the record. Stored inmetadata_lenbytes.value: The value contained in the record. Stored in the remainingrecord_length - metadata_len - 4bytes.
With, our byte layout ready, let's proceed with our Segment::append implementation:
That looks more involved than it actually is. Still, let's go through it once:
append()- Validate the append index, and obtain it if not provided.
- Serialize the metadata, specifically the
MetaWithIdxinstance in theRecord - Find the length of the serialized
metadata_bytesasmetadata_bytes_len - Serialze the
metadata_bytes_lentometadata_bytes_len_bytes - Create a sum type to generalize over serialized byte slices and record value byte slices
- Chain the byte slices in a stream in the order
[metadata_bytes_len_bytes, metadata_bytes, ...record.value] - Call
append_serialized_record()on the final chained stream of slices
append_serialized_record()- Copy current
highest_indextowrite_index - Obtain the
remaining_store_capacityusing the expressionconfig.max_store_size - store.size() append_thresholdis then the remaining capacity along with overflow bytes allowed, i.e.remaining_store_capacity + config.max_store_overflow- Append the serialized stream of slices to the underlying
Storeinstance with the computedappend_threshold - Using the
(position, index_record)obtained fromstore.append(), we create theIndexRecord - Append the
IndexRecordto the underlyingIndexinstance. - Return the
indexat which the serialized record was written, (returnwrite_index)
- Copy current
Next, we implement the AsyncIndexedRead trait for Segment using the same byte layout:
Again, let's summarize, what's happening above:
- Read the
IndexRecordat the given indexidxfrom the underlyingIndexinstance - Read the serialized record bytes using the
IndexRecordfrom the underlyingStoreinstance. - Split and deserialize the serialized record bytes to
metadata_bytes_len,metadataand recordvalue - Returns a
Recordinstance containing the readmetadataandvalue.
Segment::appendand theAsyncIndexedReadtrait impl form the majority of the responsiblities of aSegment.
Next, we need to provide an API for managing Index caching on Segment instances:
As you can see, it simply exposes the caching api of the underlying Index.
When constructing our Segment, most of the times we will need to read the Segment with a given base_index from some storage media. Ideally we want a mechanism that allows us to:
- Find the base indices of all the segments stored in some storage media
- Given a
base_index, get theStoragetrait impl. instances associated with theSegmenthaving thatbase_index
Now a Segment contains an Index and Store. Each of them have distinct underlying Storage trait impl. instances associated with them. However, they are still part of the same unit.
Let's create a struct SegmentStorage to express ths notion:
Now, let's express our notion of the storage media that provides SegmentStorage instances:
/// Provides SegmentStorage for the Segment with the given base_index from some storage media.
We rely on the SegmentStorageProvider for allocating files or other storage units for our Segment instances. The receivers are &mut since the operations presented here might need to manipulate the underlying storage media.
With SegmentStorageProvider, we can completely decouple storage media from our Segment, and by extension, our SegmentedLog implementation.
Now let's go back to our Segment. Let's create a Segment constructor that uses the SegmentStorageProvider:
Next, we utilize the SegmentStorageProvider to provide an API to flush data written in a Segment to the underlying storage media. The main idea behind flushing is to close and reopen the underlying storage handles. This method is generally a consistent method of flushing data across different storage platforms. We implement this as follows:
Finally, we implement AsyncTruncate and AsyncConsume for our Segment:
SegmentedLog (struct)
With our underlying components in place, we are ready to encapsulate the segmented-log data-structure.
Similar to Segment, we need to represent the configuration schema of our SegmentedLog first:
/// Configuration for a SegmentedLog
Next, we express our notion of a segmented-log as the SegmentedLog struct:
The generic parameters are as follows:
S:Storagetrait impl. to be used as storage foor underlyingSegmentinstancesM: Metadata to be used as parameter toMetaWithIdxin everyRecordIdx: Unsigned integer type to be used as record indicesSize: Unsigned integer type to be used as storage sizeSERP:SerializationProvidertrait impl.SSP:SegmentStorageProvidertrait impl.C:Cachetrait impl.
The Cache trait is from the crate generational-cache. It represents an abstract Cache, and is defined as follows:
/// A size bounded map, where certain existing entries are evicted to make space for new
/// entires.
/// An evicted value from cache.
Now this is all fine and dandy but you are probably wondering, "Why do we need a cache again?" Remember that if all Segment instances are Index cached, for every 1GB of record data, we need 16MB of heap memory if record sizes are 1KB. So we made Index caching optional to keep memory usage from exploding.
How do we decide which Segment instances are to cache their Index? We use another cache segments_with_cached_index to decide which Segment instances cache their Index. We can choose the cache type based on a access patterns (LRU, LFU etc.)
Now we don't need to store the Segment instances itself in the Cache implementation. We can instead store the index of the Segment instance in the read_segments vector. Also we don't need to store any explicit values in our Cache, just the keys will do. So our bound would be: Cache<usize, ()>.
However, there might be cases, where the user might want all Segment instances to cache their Index. So we also make segments_with_cached_index optional.
Next, let's implement a constructor for our SegmentedLog:
Let's summarize the above method:
- We obtain the base indices of all the
Segmentinstances persisted in the givenSegmentStorageProviderinstance insegment_base_indices. - We split the read base indices into
read_segment_base_indicesandwrite_segment_base_index.write_segment_base_indexis the last element insegment_base_indices. Ifsegment_base_indicesis empty (meaning there are noSegmentinstances persisted), we useconfig.initial_indexas thewrite_segment_base_index. The remaining base indices areread_segment_base_indices. - We create the read
Segmentinstances and the writeSegmentusing their appropriate base indices. ReadSegmentinstances are cached only ifnum_index_cached_read_segmentslimit is not set. If this limit is set, we don't inded-cache readSegmentinstances in this constructor. Instead we index-cache them when they are referenced. - We store the read
Segmentinstances in a vectorread_segments. - Write
Segmentis always cached. - We creae a
segments_with_cached_indexCacheinstance to keep track of whichSegmentinstances are currently index-cached. We limit its capacity to only as much as necessary. - With the read
Segmentvector, writeSegment,config,segments_with_cached_indexandsegment_storage_providerwe create ourSegmentedLoginstance and return it.
Before we proceed further, let's define a couple of macros to make our life a bit easier:
/// Creates a new write Segment instance with the given base_index for
/// the given SegmentedLog instance
/// Consumes the given Segment instance with the given consume_method
/// (close() or remove())
/// Takes ownership of the write Segment instance from the given
/// SegmentedLog.
/// Obtaines a reference to the write Segment in the given
/// SegmentedLog with the given ref_method.
/// (as_mut() or as_ref())
These macros are strictly meant for internal use.
With our groundwork ready, let's proceed with the read/write API for our SegmentedLog.
Now for reads, we need to be able to read Record instances by their index in the SegmentedLog. This requires us to be able to resolve which Segment contains the Record with the given index.
We know that the Segment instances are sorted by their base_index and have non-overlapping index ranges. This enables us to do a binary search on the read_segments vector to check which Segment has the given index within their index range. If none of the read Segment instances contain this index we default to the write_segment.
If the write_segment doen't contain the index, it's read API will error out.
Let's implement this behaviour:
pub type ResolvedSegmentMutResult<'a, S, M, H, Idx, SERP, C> =
;
pub type ResolvedSegmentResult<'a, S, M, H, Idx, SERP, C> =
;
Now we can implement AsyncIndexedRead for our SegmentedLog:
Notice that this API doesn't use any caching behaviour. This API has been designed to not contain any side effects and be perfectly idempotent in nature.
We need a different API to enable side effects like index-caching.
Let's introduce a new trait to achieve this:
/// Alternative to the AsyncIndexedRead trait where the invoker is guranteed
/// to have exclusive access to the implementing instance.
Next, let's implement some structs and methods for controlling the caching behaviour:
With our caching behaviour implemented, we implement the AsyncIndexedExclusiveRead trait for our SegmentedLog:
There are some other methods to read Record instances efficiently for different workloads:
read_seq: Sequentially read records in the segmented-log by sequentially iterating over the underlying segments. Avoids segment search overhead.read_seq_exclusive:read_seqwith caching behaviourstream: Returns a stream ofRecordinstances within a given range of indicesstream_unbounded:streamwith index range set to entire range of the segmented-log
Read them on the repository in the SegmentedLog module.
Next, we need to prepare for our SegmentedLog::append implementation. The basic outline of append() is as follows:
- If current write segment is maxed, rotate write segment to a read segment, and create a new write segment that start off where it left.
- Append the record to the write segment
So, we need to implemenent write segment rotation. Let's proceed:
A previous implementation used to directly close and re-open the write segment to flush it. This led to readng the index records multiple times when rotating segments. The new
Segment::flushAPI avoids doing that, making the currentrotate_new_write_segmentimplementation more efficient.
With this we are aready to implement CommitLog::append for our SegmentedLog:
Exactly, as discussed. Now let't implement the missing remove_expired_segments method:
Let's summarize what is going on above:
- Flush the write segment
- Make a copy of the current
highest_indexasnext_index. It is to be used as thebase_indexof the next write segment to be created. - Take all segments (both read and write) into a single vector
- These segments are sorted by both index and age. The ages are in descending order
- We find the first segment in this segment that is young enough to not be considered expired
- We split the vector into two parts, the ones
to_removeand the onesto_keep. The onesto_keepstarts from the first non-expired segment. The older ones are the onesto_remove - We isolate the last segment from the segments
to_keepas the write segment. If there are no segments to keep (i.eto_keepis empty), we create a new write segment withbase_indexset to the thenext_indexwe stored earlier. - We remove the segments to be removed (i.e the ones in
to_remove) from storage. We also remove their entries from the cache.
Next, let's see the AsyncTruncate trait impl. for SegmentedLog:
Let's summarize what is going on above:
- If the given index is out of bounds, error out
- If the given index is contained withing the write segment, truncate the write segment and call it a day.
- If none of the above conditions are true continue on
- Find the segment which contains the given index
- Truncate the segment at the given index
- Remove all segments that come after this segment; also remove their entries from the cache
- Create a new write segment which has it's
base_indexset to thehighest_indexof the truncated segment. Set it as the new write segment
Finally we have the AsyncConsume trait impl. for SegmentedLog:
/// Consumes all Segment instances in this SegmentedLog.
An example application using SegmentedLog
Let's summarize what we want to achieve here:
- A HTTP API server that provides RPC like endpoints for a commit log API
- Providing on disk persitence to the underlying commit log using
tokio::fsbasedStorageandSegmentStorageProviderimpls.
Recall that we already wrote a Storage impl using tokios::fs earlier here. Now we need a SegmentStorageProvider impl. However, could we do even better?
The mechanics for creating a maintaining a file hierarchy for storing segment store and index files will remain largely the same, even across different async runtimes and file implementations. What if we could also abstract that complexity away?
PathAddressedStorageProvider (trait)
A PathAddressedStorageProvider obtains Storage impl instances adrressed by paths. We don't specify at this point where those paths belong (whether on disk based fs, vfs, nfs file share etc.)
DiskBackedSegmentStorageProvider (struct)
DiskBackedSegmentStorageProvider uses a PathAddressedStorageProvider impl. instance to implement SegmentStorageProvider. The PathAddressedStorageProvider implementing instance is expected to use on-disk filesystem backed paths and consequently, return Storage instances backed on the on-disk filesystem.
// ...
Next, we will flesh out the SegmentStorageProvider implementation in detail.
First, we have some standard file extensions for Segment Store and Index files:
pub const STORE_FILE_EXTENSION: &str = "store";
pub const INDEX_FILE_EXTENSION: &str = "index";
We maintain a mostly flat hierarchy for storing our files:
storage_directory/
├─ <segment_0_base_index>.store
├─ <segment_0_base_index>.store
├─ <segment_1_base_index>.store
├─ <segment_1_base_index>.store
...
Following this hierarchy, let's implement SegmentStorageProvider for our DiskBackedSegmentStorageProvider:
With these utilities in place we can proceed with our commit log server example.
laminarmq-tokio-commit-log-server (crate)
A simple persistent commit log server using the tokio runtime.
The code for this example can be found here.
This server exposes the following HTTP endpoints:
.route // obtain the index bounds
.route // obtain the record at given index
.route // append a new record at the end of the
// commit-log
.route // truncate the commit log
// expects JSON:
// { "truncate_index": <idx: number> }
// records starting from truncate_index
// are removed
Architecture outline for our commit-log server

Fig: Architecture for our tokio based commit-log server.
As you can see, we divide the responsiblity of the commit-log server between two halves:
- axum client facing web request handler: Responsible for routing and parsing HTTP requests
- commit-log request processing: Uses an on disk persisted
CommitLogimpl instance to process different commit-log API requests
In order to process commit-log requests we run a dedicated request handler loop on it's own single threaded tokio runtime. The web client facing half forwards the parsed requests to the request processing half over a dedicated channel, collects the result and responds back to the client.
In order the complete the loop, the request processing half also sends a channel send half resp_tx, while keeping the recv half resp_rx with themselves. The request processing half sends back the result using the send half resp_tx it received.
We will be using axum for this example.
Now that we have an outline of our architecture, let's proceed with the implementation.
Request and Response types
Let's use Rust's excellent enums to represent our request and response types:
Why did we use structs for certain enum values? Well, we will be using those structs later for parsing json requests in
axumroutes.
Now recall that we will be communicating between the axum server task and the commit-log request processing task. Let's define a Message type to encode the medium of communication.
type ResponseResult = ;
/// Unit of communication between the client facing task and the request
/// processing task
Commit Log server config
We also need to two configurable paramters. Let's define them in a struct:
/// Configuration for the commit-log request processing server.
Commit Log server request handler
With the pre-requisites ready, let's proceed with actually processing our commit-log requests.
First, we need a struct to manage commit-log server instances:
/// Abstraction to process commit-log requests
Here CL is a type implementing the CommitLog trait.
There's also an error type and a few aliases to make life easier. Feel free to look them up in the repository.
Next, we define our request handler that maps every request to it's corresponding response using the CommitLog impl instance:
Notice that we are directly passing in
Bodyto ourCommitLog::append()without usingto_bytes(). This is possible becauseBodyimplementsStream<Result<Bytes, _>>which satisfies the trait boundStream<Result<Deref<Target = [u8]>, _>>. This allows us to write the entire request body in a streaming manner without concatenating the intermediate (packet) buffers. (SeeCommitLogandStoragefor a refresher.)
The above implementation is fairly straightforward: there is a one-to-one mapping between the request, the commit-log methods and the responses.
Commit Log server task managment and orchestration
As discussed before, we run our commit-log server tasks and request handling loop in single-threaded tokio runtime.
However, let's first derive a basic outline of the request handling loop. In the simplest form, it could be something as follows:
while let Some = message_rx.recv.await
Notice that we explicitly match on Message::Connection so that we can exit the loop when we receive a Message::Terminate.
Now we want to service multiple connections concurrently. Sure. Does this work?
while let Some = message_rx.recv.await
Almost. We just need to impose concurrency control. Let's do that:
while let Some = message_rx.recv.await
Let us now look at the actual implementation:
Don't sweat the individual details too much. However, try to see how this implementation fleshes out the basic outline we derived a bit earlier.
Finally, we need to orchestrate the serve() function inside a single threaded tokio runtime:
All this method does is setup the channel for receiving messages, spawn a thread, create a single threaded rt in it and then call serve() within the single-threaded rt.
We return the JoinHandle and the channel send end Sender from this function. They allow us to join() the spawned thread and send Message instances to our CommitLogServer respectively.
Client facing axum server
Let's now move on to the client facing end of our commit-log server. This side has three major responsiblities:
- Parse HTTP Requests to appropriate
AppRequestinstances using the request path and body - Send a
Message::Connectioncontaining the parsedAppRequestto theCommitLogServer - Retrieve the response from the
CommitLogServerusing the connections receive end and respond back to the user
Our axum app state simply needs to contain the message channel Sender. We also add a method to making enqueuing requests easier:
Our route handler functions will be mostly identical. I will show the read and append route handlers here. Feel free to read the rest of the route handlers here
// ...
async
async
// ...
Finally, we have our main() function for our binary:
async
Feel free to checkout the remaining sections of the commit-log server implementation here
Closing notes
This blog discussed a segmented-log implementation right from the theoretical foundations, to a production level library. At the end of the implementation, we explored an example commit-log server using our segmented-log implementation.
Read more about laminarmq milestones here
References
We utilized the following resources as references for this blog post:
Lamport, Leslie. "Time, clocks, and the ordering of events in a distributed system." Concurrency: the Works of Leslie Lamport. 2019. 179-196. https://dl.acm.org/doi/pdf/10.1145/359545.359563
Jay Kreps. "The Log: What every software engineer should know about real-time data's unifying abstraction." LinkedIn engineering blog. 2013. https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
Kreps, Jay, Neha Narkhede, and Jun Rao. "Kafka: A distributed messaging system for log processing." Proceedings of the NetDB. Vol. 11. No. 2011. 2011. https://pages.cs.wisc.edu/~akella/CS744/F17/838-CloudPapers/Kafka.pdf